1.1 Global Proteomics Data
This pipeline shows how to process TMT data that is processed outside of PNNL’s DMS. Section 1.2 shows how to process data from the DMS. For convenience, the results of MS-GF+ and MASIC processing are provided in a companion PlexedPiperTestData package. In addition, we will need PlexedPiper for isobaric quantification, dplyr to manipulate data frames, and MSnbase to create MSnSet objects.
# Setup
library(PlexedPiper)
library(PlexedPiperTestData)
library(dplyr)The pipeline can be broken up into 4 major chunks: prepare MS/MS identifications, prepare reporter ion intensities, create a quantitative cross-tab, and create an MSnSet object.
1.1.1 Read MS-GF+ Data
The first step in the preparation of the MS/MS identifications is to fetch the data. In this case, the data exists in the PlexedPiperTestData package in a local folder, so we use system.file to get the file path and read_msgf_data to read the MS-GF+ output.
# Get file path
path_to_MSGF_results <- system.file("extdata/global/msgf_output",
package = "PlexedPiperTestData")
# Read MS-GF+ data from path
msnid <- read_msgf_data(path_to_MSGF_results)Normally, this would display a progress bar in the console as the data is being fetched. However, the output was suppressed to save space. We can view a summary of the MSnID object with the show() function.
show(msnid)## MSnID object
## Working directory: "."
## #Spectrum Files: 48
## #PSMs: 1156754 at 31 % FDR
## #peptides: 511617 at 61 % FDR
## #accessions: 128378 at 98 % FDRThis summary tells us that msnid consists of 4 spectrum files (datasets), and contains a total of 1,156,754 peptide-spectrum-matches (PSMs), 511,617 total peptides, and 128,378 total accessions (proteins). The reported FDR is the empirical false-discovery rate, which is calculated as the ratio of the number of false (decoy) PSMs, peptides, or accessions to their true (non-decoy) counterparts. Calculation of these counts and their FDRs is shown below.
# How to calculate the counts and FDRs from the show() output
## Spectrum Files
# Count
psms(msnid) %>%
distinct(Dataset) %>%
nrow() # 48
## PSMs
# Count
psms(msnid) %>%
distinct(Dataset, Scan, peptide, isDecoy) %>%
# Assign intermediate to variable
assign("x_psm", ., envir = globalenv()) %>%
nrow() # 1156754
# FDR
nrow(x_psm[x_psm$isDecoy == TRUE, ]) /
nrow(x_psm[x_psm$isDecoy == FALSE, ])
# 0.3127463 = 31%
## peptides
# Count
psms(msnid) %>%
distinct(peptide, isDecoy) %>%
assign("x_peptide", ., envir = globalenv()) %>%
nrow() # 511617
# FDR
nrow(x_peptide[x_peptide$isDecoy == TRUE, ]) /
nrow(x_peptide[x_peptide$isDecoy == FALSE, ])
# 0.611245 = 61%
## accessions
# Count
length(accessions(msnid)) # or
psms(msnid) %>%
distinct(accession, isDecoy) %>%
assign("x_acc", ., envir = globalenv()) %>%
nrow() # 128378
# FDR
nrow(x_acc[x_acc$isDecoy == TRUE, ]) /
nrow(x_acc[x_acc$isDecoy == FALSE, ])
# 0.9827024 = 98%Now that we have an MSnID object, we need to process it. We begin by correcting for the isotope selection error.
1.1.2 Correct Isotope Selection Error
Carbon has two stable isotopes: \(^{12}\text{C}\) and \(^{13}\text{C}\), with natural abundances of 98.93% and 1.07%, respectively. That is, we expect that about 1 out of every 100 carbon atoms is naturally going to be a \(^{13}\text{C}\), while the rest are \(^{12}\text{C}\). In larger peptides with many carbon atoms, it is more likely that at least one atom will be a \(^{13}\text{C}\) than all atoms will be \(^{12}\text{C}\). In cases such as these, a non-monoisotopic ion will be selected by the instrument for fragmentation.
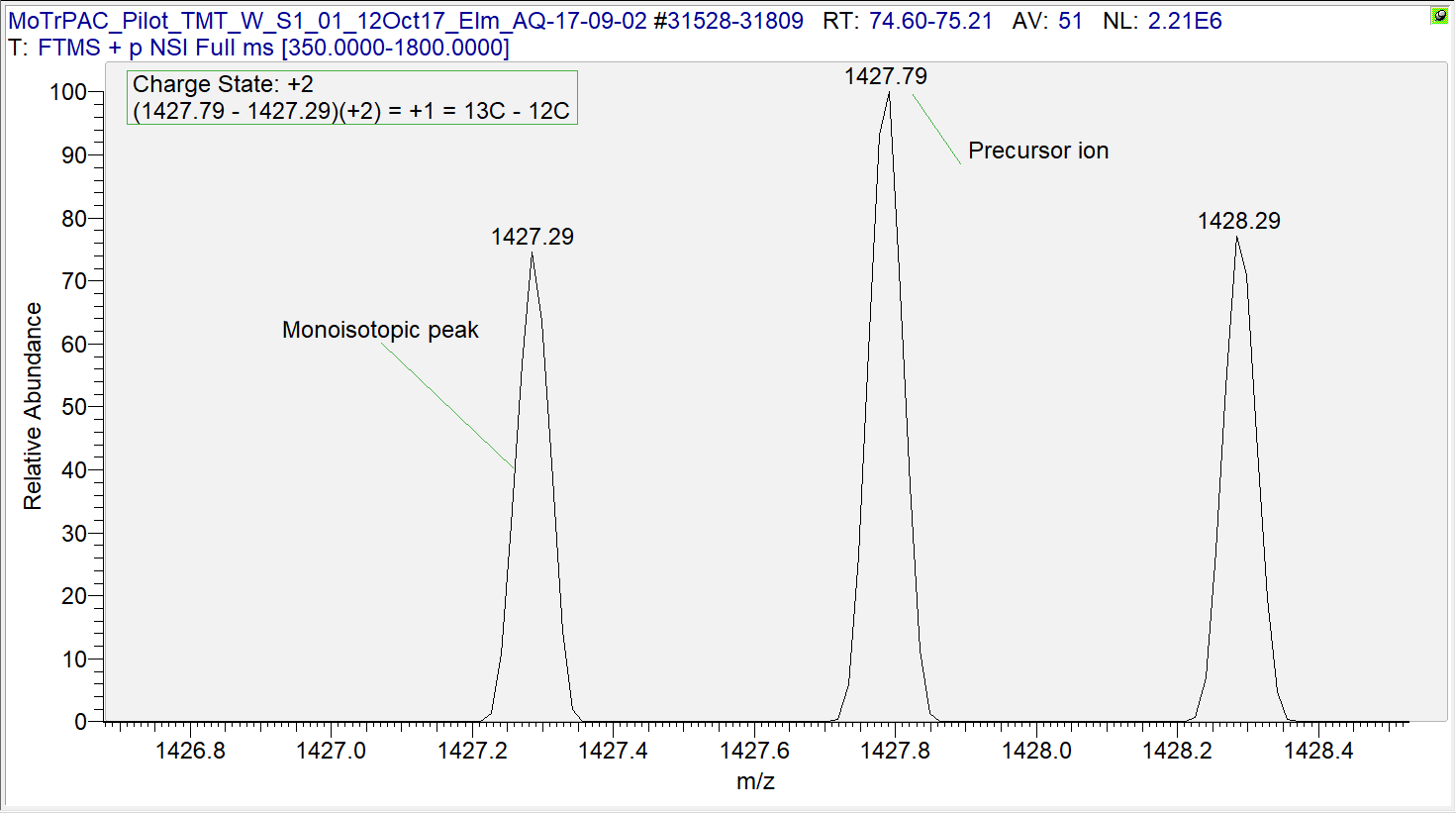
(#fig:MS1_peak)MS1 spectra with peak at non-monoisotopic precursor ion.
In Figure @ref(fig:MS1_peak), the monoisotopic ion (m/z of 1427.29) is not the most abundant, so it is not selected as the precursor. Instead, the ion with a \(^{13}\text{C}\) in place of a \(^{12}\text{C}\) is selected for fragmentation. We calculate the mass difference between these two ions as the difference between the mass-to-charge ratios multiplied by the ion charge. In this case, the mass difference is 1 Dalton, or about the difference between \(^{13}\text{C}\) and \(^{12}\text{C}\). (More accurately, the difference between these isotopes is 1.0033548378 Da.) While MS-GF+ is still capable of correctly identifying these peptides, the downstream calculations of mass measurement error need to be fixed because they are used for filtering later on (Section 1.1.4). The correct_peak_selection function corrects these mass measurement errors, and Figure 1.1 shows the distribution of the mass measurement errors before and after correction.
# Correct for isotope selection error
msnid <- correct_peak_selection(msnid)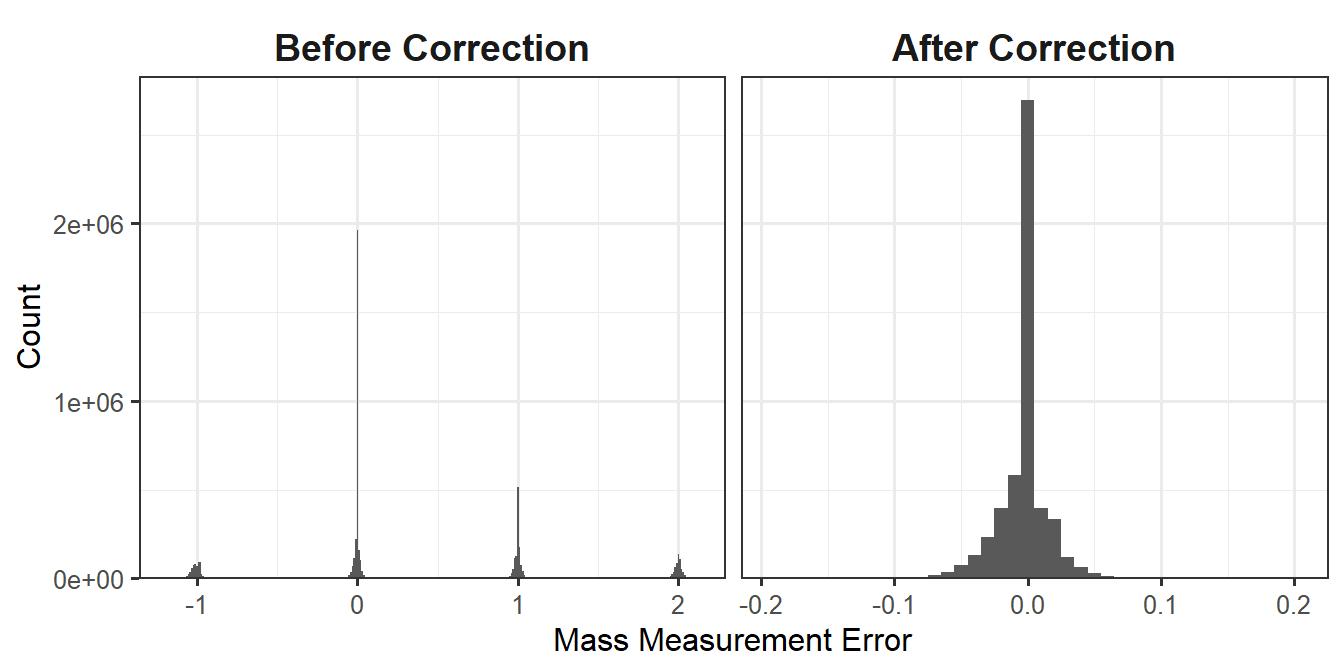
Figure 1.1: Histogram of mass measurement errors before and after correction.
1.1.3 Remove Contaminants
Now, we will remove contaminants such as the trypsin that was used for protein digestion. We can use grepl to search for all accessions that contain the string "Contaminant". Displaying these contaminants is not necessary during processing. This is just for demonstration purposes to see what will be removed.
# All unique contaminants
accessions(msnid)[grepl("Contaminant", accessions(msnid))]## [1] "Contaminant_K2C1_HUMAN" "Contaminant_K1C9_HUMAN"
## [3] "Contaminant_ALBU_HUMAN" "Contaminant_ALBU_BOVIN"
## [5] "Contaminant_TRYP_PIG" "Contaminant_K1C10_HUMAN"
## [7] "XXX_Contaminant_K1C9_HUMAN" "Contaminant_K22E_HUMAN"
## [9] "Contaminant_Trypa3" "Contaminant_Trypa5"
## [11] "XXX_Contaminant_K1C10_HUMAN" "XXX_Contaminant_K22E_HUMAN"
## [13] "XXX_Contaminant_K2C1_HUMAN" "Contaminant_TRYP_BOVIN"
## [15] "XXX_Contaminant_ALBU_HUMAN" "XXX_Contaminant_ALBU_BOVIN"
## [17] "XXX_Contaminant_TRYP_BOVIN" "Contaminant_CTRB_BOVIN"
## [19] "Contaminant_Trypa1" "Contaminant_Trypa6"
## [21] "Contaminant_CTRA_BOVIN" "XXX_Contaminant_TRYP_PIG"
## [23] "XXX_Contaminant_CTRB_BOVIN" "XXX_Contaminant_CTRA_BOVIN"
## [25] "Contaminant_Trypa2"To remove contaminants, we use apply_filter with an appropriate character string that tells the function what rows to keep. In this case, we keep rows where the accession does not contain “Contaminant.” We will use show to see how the counts change.
# Remove contaminants
msnid <- apply_filter(msnid, "!grepl('Contaminant', accession)")
show(msnid)## MSnID object
## Working directory: "."
## #Spectrum Files: 48
## #PSMs: 1155442 at 31 % FDR
## #peptides: 511196 at 61 % FDR
## #accessions: 128353 at 98 % FDRWe can see that the number of PSMs decreased by about 1300, peptides by ~400, and proteins by 25 (the 25 contaminants that were displayed).
1.1.4 MS/MS ID Filter: Peptide Level
The next step is to filter the MS/MS identifications such that the empirical peptide-level FDR is less than some threshold and the number of MS/MS IDs is maximized. We will use the \(-log_{10}\) of the PepQValue column as one of our filtering criteria and assign it to a new column in psms(msnid) called msmsScore. The PepQValue column is the MS-GF+ Spectrum E-value, which reflects how well the theoretical and experimental fragmentation spectra match; therefore, high values of msmsScore indicate a good match (see Figure 1.2).
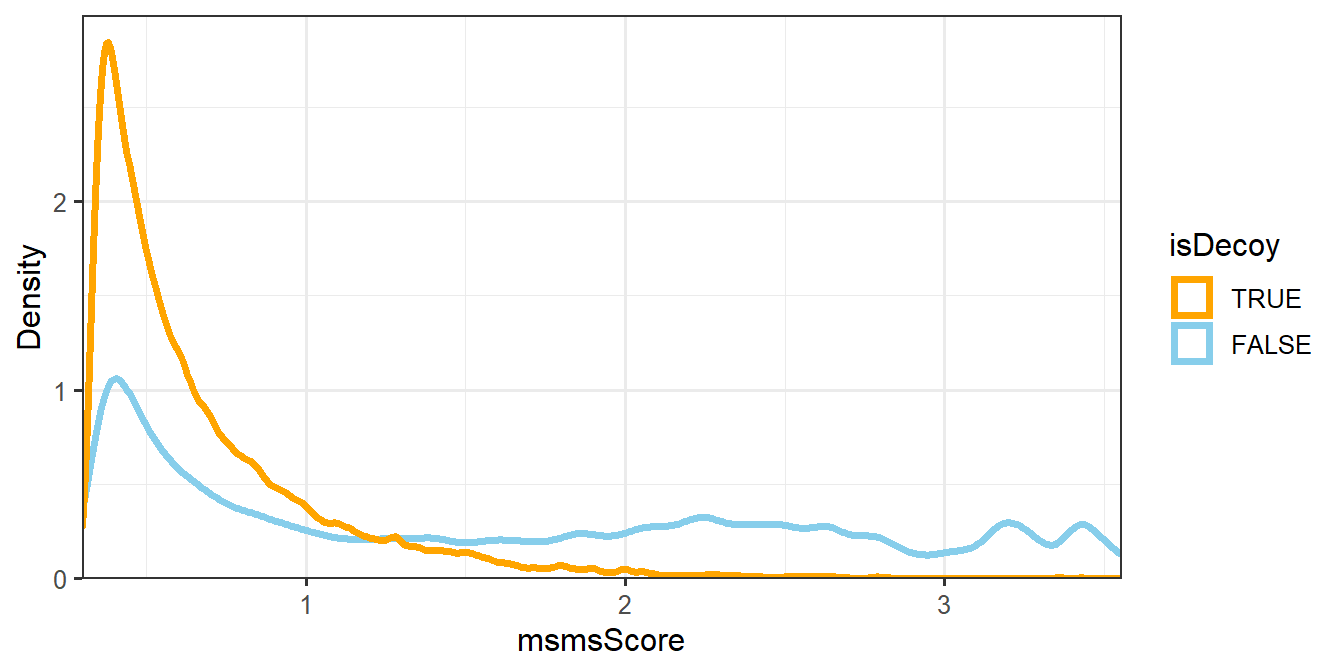
Figure 1.2: Density plot of msmsScore.
The other filtering criteria is the absolute deviation of the mass measurement error of the precursor ions in parts-per-million (ppm), which is assigned to the absParentMassErrorPPM column in psms(msnid) (see Figure 1.3).
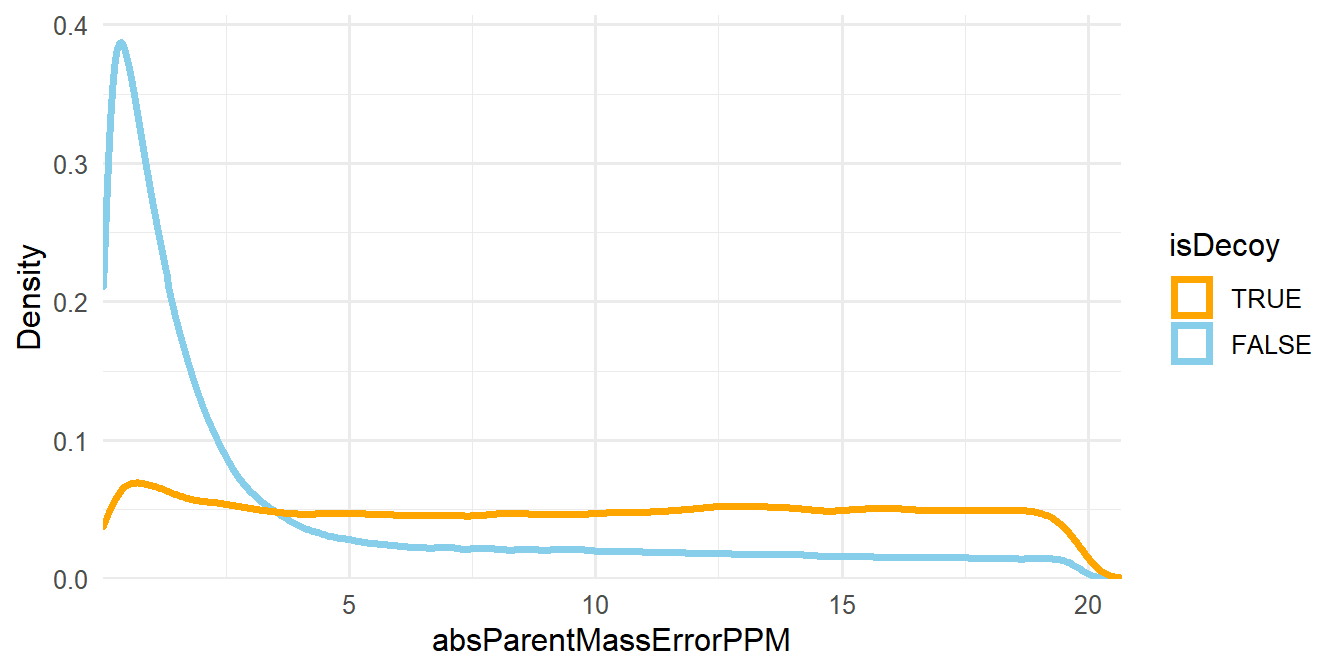
Figure 1.3: Density plot of absParentMassErrorPPM.
Now, we will filter the PSMs.
# 1% FDR filter at the peptide level
msnid <- filter_msgf_data(msnid,
level = "peptide",
fdr.max = 0.01)
show(msnid)## MSnID object
## Working directory: "."
## #Spectrum Files: 48
## #PSMs: 464474 at 0.45 % FDR
## #peptides: 96485 at 1 % FDR
## #accessions: 27119 at 9.2 % FDRWe can see that filtering drastically reduces the number of PSMs, and the empirical peptide-level FDR is now 1%. However, notice that the empirical protein-level FDR is still fairly high.
1.1.5 MS/MS ID Filter: Protein Level
Now, we need to filter proteins so that the FDR is at most 1%. A while ago, the proteomics field established the hard-and-fast two-peptides-per-protein rule. That is, the confident identification of a protein requires the confident identification of at least 2 peptides. This rule penalizes short proteins and doesn’t consider that there are some very long proteins (e.g. Titin 3.8 MDa) that easily have more then two matching peptides even in the reversed sequence. Thus, we propose to normalize the number of peptides per protein length and use that as a filtering criterion (Figure 1.5).
In order to get the protein lengths, we need the FASTA (pronounced FAST-AYE) file that contains the protein sequences used in the database search. The first three entries of the FASTA file are shown in Figure 1.4.

Figure 1.4: First three entries of the FASTA file.
For each protein, we divide the number of associated peptides by the length of that protein and multiply this value by 1000. This new peptides_per_1000aa column is used as the filter criteria.
# Get path to FASTA file
path_to_FASTA <- system.file(
"extdata/Rattus_norvegicus_NCBI_RefSeq_2018-04-10.fasta.gz",
package = "PlexedPiperTestData"
)
# Compute number of peptides per 1000 amino acids
msnid <- compute_num_peptides_per_1000aa(msnid, path_to_FASTA)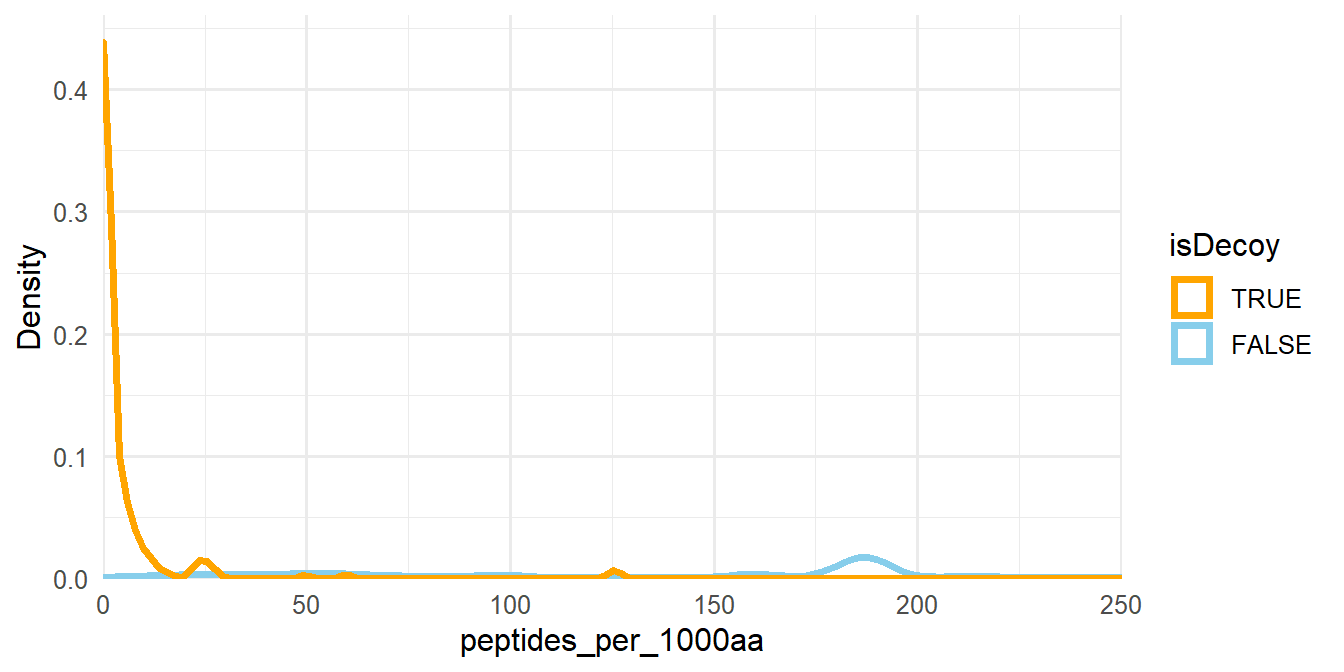
Figure 1.5: Density plot of peptides_per_1000aa. The plot area has been zoomed in.
Now, we filter the proteins to 1% FDR.
# 1% FDR filter at the protein level
msnid <- filter_msgf_data(msnid,
level = "accession",
fdr.max = 0.01)
show(msnid)## MSnID object
## Working directory: "."
## #Spectrum Files: 48
## #PSMs: 458090 at 0.16 % FDR
## #peptides: 92036 at 0.32 % FDR
## #accessions: 15630 at 1 % FDR1.1.6 Inference of Parsimonious Protein Set
The situation when a certain peptide sequence matches multiple proteins adds complication to the downstream quantitative analysis, as it is not clear which protein this peptide is originating from. There are common ways for dealing with this. One is to simply retain uniquely matching peptides and discard shared peptides (unique_only = TRUE). Alternatively, assign the shared peptides to the proteins with the larger number of uniquely mapping peptides (unique_only = FALSE). If there is a choice between multiple proteins with equal numbers of uniquely mapping peptides, the shared peptides are assigned to the first protein according to alphanumeric order (Figure 1.6).
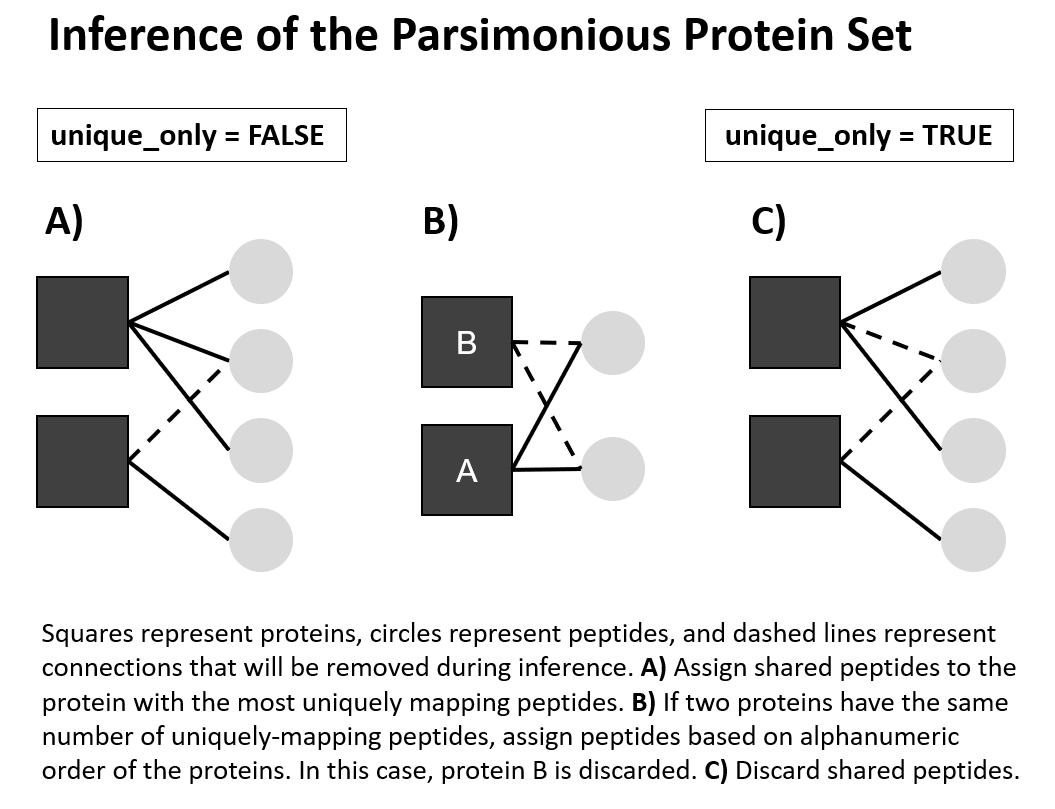
Figure 1.6: Visual explanation of the inference of the parsimonious protein set.
# Inference of parsimonious protein set
msnid <- infer_parsimonious_accessions(msnid, unique_only = FALSE)
show(msnid)## MSnID object
## Working directory: "."
## #Spectrum Files: 48
## #PSMs: 444999 at 0.15 % FDR
## #peptides: 90478 at 0.27 % FDR
## #accessions: 5251 at 1.1 % FDRNotice that the protein-level FDR increased slightly above the 1% threshold. In this case, the difference isn’t significant, so we can ignore it.
Note:
If the peptide or accession-level FDR increases significantly above 1% after inference of the parsimonious protein set, consider lowering the FDR cutoff (for example, to 0.9%) and redoing the previous processing steps. Filtering at the peptide and accession level should each be done a single time.
1.1.7 Remove Decoy PSMs
The final step in preparing the MS/MS identifications is to remove the decoy PSMs. We use the apply_filter function again and only keep entries where isDecoy is FALSE.
# Remove Decoy PSMs
msnid <- apply_filter(msnid, "!isDecoy")
show(msnid)## MSnID object
## Working directory: "."
## #Spectrum Files: 48
## #PSMs: 444338 at 0 % FDR
## #peptides: 90232 at 0 % FDR
## #accessions: 5196 at 0 % FDRAfter processing, we are left with 444,345 PSMs, 90,232 peptides, and 5,196 proteins. Table 1.1 shows the first 6 rows of the processed MS-GF+ output.
| Dataset | ResultID | Scan | FragMethod | SpecIndex | Charge | PrecursorMZ | DelM | DelM_PPM | MH | peptide | Protein | NTT | DeNovoScore | MSGFScore | MSGFDB_SpecEValue | Rank_MSGFDB_SpecEValue | EValue | QValue | PepQValue | IsotopeError | accession | calculatedMassToCharge | chargeState | experimentalMassToCharge | isDecoy | spectrumFile | spectrumID | pepSeq | msmsScore | absParentMassErrorPPM | peptides_per_1000aa |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MoTrPAC_Pilot_TMT_W_S1_07_12Oct17_Elm_AQ-17-09-02 | 1862 | 27707 | HCD | 324 | 2 | 928.541 | -0.001 | -0.526 | 1856.075 | R.AAAAAAAAAAAAAAGAAGK.E | NP_113986.1 | 2 | 285 | 282 | 0 | 1 | 0 | 0.000 | 0.000 | 0 | NP_113986.1 | 928.541 | 2 | 928.541 | FALSE | MoTrPAC_Pilot_TMT_W_S1_07_12Oct17_Elm_AQ-17-09-02 | 27707 | AAAAAAAAAAAAAAGAAGK | Inf | 0.589 | 25.769 |
| MoTrPAC_Pilot_TMT_W_S1_07_12Oct17_Elm_AQ-17-09-02 | 4192 | 27684 | HCD | 906 | 3 | 619.363 | -0.002 | -0.887 | 1856.075 | R.AAAAAAAAAAAAAAGAAGK.E | NP_113986.1 | 2 | 156 | 144 | 0 | 1 | 0 | 0.000 | 0.000 | 0 | NP_113986.1 | 619.363 | 3 | 619.363 | FALSE | MoTrPAC_Pilot_TMT_W_S1_07_12Oct17_Elm_AQ-17-09-02 | 27684 | AAAAAAAAAAAAAAGAAGK | Inf | 0.991 | 25.769 |
| MoTrPAC_Pilot_TMT_W_S2_06_12Oct17_Elm_AQ-17-09-02 | 26263 | 27336 | HCD | 5187 | 3 | 619.363 | 0.000 | 0.197 | 1856.075 | R.AAAAAAAAAAAAAAGAAGK.E | NP_113986.1 | 2 | 118 | 85 | 0 | 1 | 0 | 0.000 | 0.000 | 0 | NP_113986.1 | 619.363 | 3 | 619.363 | FALSE | MoTrPAC_Pilot_TMT_W_S2_06_12Oct17_Elm_AQ-17-09-02 | 27336 | AAAAAAAAAAAAAAGAAGK | Inf | 0.091 | 25.769 |
| MoTrPAC_Pilot_TMT_W_S2_07_12Oct17_Elm_AQ-17-09-02 | 1471 | 27096 | HCD | 415 | 3 | 619.363 | -0.001 | -0.591 | 1856.075 | R.AAAAAAAAAAAAAAGAAGK.E | NP_113986.1 | 2 | 157 | 156 | 0 | 1 | 0 | 0.000 | 0.000 | 0 | NP_113986.1 | 619.363 | 3 | 619.363 | FALSE | MoTrPAC_Pilot_TMT_W_S2_07_12Oct17_Elm_AQ-17-09-02 | 27096 | AAAAAAAAAAAAAAGAAGK | Inf | 0.684 | 25.769 |
| MoTrPAC_Pilot_TMT_W_S2_05_12Oct17_Elm_AQ-17-09-02 | 28664 | 10441 | HCD | 4849 | 2 | 586.832 | -0.001 | -0.728 | 1172.659 | R.AAAAADLANR.S | NP_001007804.1 | 2 | 124 | 124 | 0 | 1 | 0 | 0.002 | 0.003 | 0 | NP_001007804.1 | 586.833 | 2 | 586.832 | FALSE | MoTrPAC_Pilot_TMT_W_S2_05_12Oct17_Elm_AQ-17-09-02 | 10441 | AAAAADLANR | 2.480 | 0.746 | 34.755 |
| MoTrPAC_Pilot_TMT_W_S1_24_12Oct17_Elm_AQ-17-09-02 | 41775 | 8033 | HCD | 7889 | 2 | 831.447 | 0.000 | 0.000 | 1661.886 | G.AAAAAEAESGGGGGK.K | NP_001128630.1 | 1 | 176 | 76 | 0 | 1 | 0 | 0.001 | 0.003 | 0 | NP_001128630.1 | 831.447 | 2 | 831.447 | FALSE | MoTrPAC_Pilot_TMT_W_S1_24_12Oct17_Elm_AQ-17-09-02 | 8033 | AAAAAEAESGGGGGK | 2.583 | 0.106 | 580.844 |
1.1.8 Read MASIC Output
MASIC is a tool for extracting ion intensities. With proper parameter settings, it can be used for extracting TMT (or iTRAQ) reporter ion intensities. In addition, it reports a number of other helpful metrics. Notably, the interference score at the precursor ion level and the signal-to-noise ratio (S/N) at the reporter ion level (computed by Thermo software). The interference score reflects the proportion of the ion population that was isolated for fragmentation that is due to the targeted ion. In other words, 1 - InterferenceScore is due to co-isolated species that have similar elution time and precursor ion m/z. The first step in the preparation of the reporter ion intensity data is to read the MASIC results. We use a local file path and the read_masic_data function. By default, the interference score is not included, so we need to set that argument to TRUE in order to filter the results.
# Path to MASIC data
path_to_MASIC_results <- system.file("extdata/global/masic_output",
package = "PlexedPiperTestData")
# Read MASIC data
masic_data <- read_masic_data(path_to_MASIC_results, interference_score = TRUE)Normally, this would display progress bars in the console as the data is being fetched. However, the output was suppressed to save space.
| Dataset | ScanNumber | Collision.Mode | ParentIonMZ | BasePeakIntensity | BasePeakMZ | ReporterIonIntensityMax | Ion_126.128 | Ion_127.125 | Ion_127.131 | Ion_128.128 | Ion_128.134 | Ion_129.131 | Ion_129.138 | Ion_130.135 | Ion_130.141 | Ion_131.138 | Weighted.Avg.Pct.Intensity.Correction | Ion_126.128_SignalToNoise | Ion_127.125_SignalToNoise | Ion_127.131_SignalToNoise | Ion_128.128_SignalToNoise | Ion_128.134_SignalToNoise | Ion_129.131_SignalToNoise | Ion_129.138_SignalToNoise | Ion_130.135_SignalToNoise | Ion_130.141_SignalToNoise | Ion_131.138_SignalToNoise | Ion_126.128_Resolution | Ion_127.125_Resolution | Ion_127.131_Resolution | Ion_128.128_Resolution | Ion_128.134_Resolution | Ion_129.131_Resolution | Ion_129.138_Resolution | Ion_130.135_Resolution | Ion_130.141_Resolution | Ion_131.138_Resolution | ParentIonIndex | MZ | SurveyScanNumber | OptimalPeakApexScanNumber | PeakApexOverrideParentIonIndex | CustomSICPeak | PeakScanStart | PeakScanEnd | PeakScanMaxIntensity | PeakMaxIntensity | PeakSignalToNoiseRatio | FWHMInScans | PeakArea | ParentIonIntensity | PeakBaselineNoiseLevel | PeakBaselineNoiseStDev | PeakBaselinePointsUsed | StatMomentsArea | CenterOfMassScan | PeakStDev | PeakSkew | PeakKSStat | StatMomentsDataCountUsed | InterferenceScore |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MoTrPAC_Pilot_TMT_W_S1_01_12Oct17_Elm_AQ-17-09-02 | 2 | hcd | 407.74 | 227695.44 | 407.741 | 92236.87 | 70562.39 | 24864.62 | 17165.80 | 35625.00 | 92236.87 | 9640.23 | 8578.05 | 6996.69 | 11833.07 | 32281.34 | 0 | 71.47 | 25.17 | 17.38 | 36.04 | 93.32 | 9.75 | 8.67 | 7.07 | 11.96 | 32.71 | 44102 | 42700 | 42100 | 41800 | 44404 | 40500 | 39500 | 36800 | 41100 | 42302 | 0 | 407.742 | 1 | 12 | -1 | 0 | 1 | 19 | 12 | 2901600 | 211.000 | 5 | 50422000 | 2579600 | 13750 | 97562 | 10113 | 47031000 | 11 | 5.68 | -0.189 | 0.353 | 10 | 0.996 |
| MoTrPAC_Pilot_TMT_W_S1_01_12Oct17_Elm_AQ-17-09-02 | 3 | hcd | 396.72 | 59127.97 | 529.294 | 34294.90 | 23706.89 | 13559.32 | 5856.83 | 16322.71 | 34294.90 | 4853.11 | 7938.24 | 0.00 | 1465.03 | 18182.27 | 0 | 26.12 | 14.94 | 6.45 | 17.97 | 37.77 | 5.34 | 8.74 | NA | 1.61 | 19.93 | 42702 | 41100 | 37000 | 40400 | 43404 | 36400 | 39700 | NA | 29800 | 41802 | 1 | 396.718 | 1 | 12 | -1 | 0 | 1 | 19 | 12 | 2181900 | 19.690 | 5 | 34508000 | 1690600 | 110841 | 1120000 | 10166 | 31578000 | 11 | 5.59 | -0.217 | 0.347 | 10 | 0.993 |
| MoTrPAC_Pilot_TMT_W_S1_01_12Oct17_Elm_AQ-17-09-02 | 4 | hcd | 438.23 | 110444.82 | 362.224 | 14053.40 | 12459.86 | 11785.91 | 10932.51 | 10653.32 | 12328.62 | 5959.86 | 9905.82 | 8387.04 | 11166.70 | 14053.40 | 0 | 12.40 | 11.75 | 10.90 | 10.64 | 12.31 | 5.96 | 9.91 | 8.40 | 11.18 | 14.13 | 42006 | 40702 | 41402 | 40700 | 40400 | 38800 | 40200 | 38900 | 40400 | 41002 | 2 | 438.227 | 1 | 131 | 18 | 0 | 1 | 114 | 107 | 8255600 | 9.465 | 44 | 444610000 | 658727 | 872195 | 2620000 | 10129 | 343470000 | 82 | 22.80 | -0.626 | 1.099 | 89 | 1.000 |
| MoTrPAC_Pilot_TMT_W_S1_01_12Oct17_Elm_AQ-17-09-02 | 5 | hcd | 481.50 | 37082.72 | 206.466 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0 | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | 3 | 481.505 | 1 | 23 | -1 | 0 | 1 | 52 | 23 | 401824 | 27.990 | 23 | 16244000 | 344491 | 14356 | 65777 | 10109 | 14899000 | 26 | 14.10 | 0.054 | 0.504 | 39 | 1.000 |
| MoTrPAC_Pilot_TMT_W_S1_01_12Oct17_Elm_AQ-17-09-02 | 6 | hcd | 549.28 | 21077.05 | 128.129 | 21077.05 | 0.00 | 10998.67 | 0.00 | 21077.05 | 2725.50 | 0.00 | 0.00 | 0.00 | 0.00 | 6800.70 | 0 | NA | 9.19 | NA | 17.57 | 2.27 | NA | NA | NA | NA | 5.66 | NA | 40302 | NA | 42102 | 46600 | NA | NA | NA | NA | 40300 | 4 | 549.279 | 1 | 15 | -1 | 0 | 1 | 16 | 15 | 363656 | 0.700 | 5 | 5941200 | 347071 | 519640 | 1990000 | 10109 | 2528900 | 15 | 2.49 | -0.583 | 0.430 | 5 | 1.000 |
| MoTrPAC_Pilot_TMT_W_S1_01_12Oct17_Elm_AQ-17-09-02 | 8 | hcd | 388.72 | 40605.85 | 356.719 | 8087.76 | 6166.82 | 1371.27 | 2418.35 | 8087.76 | 5485.35 | 0.00 | 0.00 | 1543.48 | 1943.96 | 7436.60 | 0 | 6.92 | 1.54 | 2.71 | 9.04 | 6.13 | NA | NA | 1.72 | 2.16 | 8.26 | 40000 | 26400 | 30400 | 40400 | 44300 | NA | NA | 28800 | 28500 | 38700 | 5 | 388.720 | 7 | 12 | -1 | 0 | 1 | 30 | 12 | 478135 | 28.710 | 19 | 10718000 | 291189 | 16653 | 142562 | 10142 | 9961100 | 16 | 8.60 | -0.051 | 0.283 | 18 | 0.969 |
Table 1.2 shows the first 6 rows of masic_data.
1.1.9 Filter MASIC Data
The only other step in reporter ion intensity data preparation is to filter the results. Currently, we recommend keeping entries where at least 50% of the ion population is due to the targeted ion (interference score \(\geq\) 0.5) and not filtering by S/N.
# Filter MASIC data
masic_data <- filter_masic_data(masic_data,
interference_score_threshold = 0.5,
s2n_threshold = 0)1.1.10 Create Study Design Tables
To convert from PSMs and reporter ion intensities to meaningful quantitative data, it is necessary to know what are the samples in the reporter channels and what is the intended reference channel (or combination of channels). The entire study design is captured by three tables - fractions, samples, references. With newly processed data, these typically do not exist, and must be created. The next sections show how to create these tables.
1.1.11 Fractions
The fractions table consists of two columns: Dataset and PlexID. The Dataset column contains all of the unique datasets from msnid$Dataset or masic_data$Dataset. The PlexID column contains the plex ID associated with each dataset, and is typically an “S” followed by a number (“S1,” “S2,” etc.). We can extract the plex ID from the datasets. In this case, the plex ID always comes after “W,” so we can use a regular expression (regex) to capture it (the first argument of gsub). The regex below says to capture an “S” followed by a single digit that appears after “W” and before an underscore.
# Create fractions table
fractions <- data.frame(Dataset = unique(masic_data$Dataset)) %>%
mutate(PlexID = gsub(".*_W_(S\\d{1})_.*", "\\1", Dataset))| Dataset | PlexID |
|---|---|
| MoTrPAC_Pilot_TMT_W_S1_01_12Oct17_Elm_AQ-17-09-02 | S1 |
| MoTrPAC_Pilot_TMT_W_S1_02_12Oct17_Elm_AQ-17-09-02 | S1 |
| MoTrPAC_Pilot_TMT_W_S1_03_12Oct17_Elm_AQ-17-09-02 | S1 |
| MoTrPAC_Pilot_TMT_W_S1_04_12Oct17_Elm_AQ-17-09-02 | S1 |
| MoTrPAC_Pilot_TMT_W_S1_05_12Oct17_Elm_AQ-17-09-02 | S1 |
| MoTrPAC_Pilot_TMT_W_S1_06_12Oct17_Elm_AQ-17-09-02 | S1 |
| MoTrPAC_Pilot_TMT_W_S1_07_12Oct17_Elm_AQ-17-09-02 | S1 |
| MoTrPAC_Pilot_TMT_W_S1_08_12Oct17_Elm_AQ-17-09-02 | S1 |
| MoTrPAC_Pilot_TMT_W_S1_09_12Oct17_Elm_AQ-17-09-02 | S1 |
| MoTrPAC_Pilot_TMT_W_S1_10_12Oct17_Elm_AQ-17-09-02 | S1 |
Table 1.3 shows the first 10 rows of fractions.
1.1.12 Samples
The samples table contains columns PlexID, QuantBlock, ReporterName, ReporterAlias, and MeasurementName. The plex ID must be the same as the plex ID in the fractions table. ReporterName is the reporter ion name (“126,” “127N,” “127C,” etc.). ReporterAlias is the intermediate between ReporterName and MeasurementName and is used for defining the reference. MeasurementName determines the column names for the final cross-tab, and must be unique and begin with a letter. Finally, QuantBlock can be thought of as a way of defining sub-plex. In a typical TMT experiment, QuantBlock is always 1. In case of 5 pairwise comparisons within TMT10, there will be 5 QuantBlocks (1-5) with a reference for each QuantBlock.
For this experiment, channel 131 will serve as the reference, so we set MeasurementName to NA when ReporterName is "131". This will make the reference channel absent from the quantitative cross-tab. In cases where reporter ion intensities are not normalized by a reference channel (reference = 1) or they are normalized by the average of select channels, do not set any MeasurementName to NA.
# Create samples table
samples <- read.delim("data/MoTrPAC_pilot_TMT_labeling.txt") %>%
dplyr::rename(ReporterName = TMT10_channel,
ReporterAlias = sample_ID) %>%
mutate(QuantBlock = 1,
MeasurementName = ifelse(ReporterAlias == "ref", NA, ReporterAlias))| ReporterAlias | ReporterName | PlexID | QuantBlock | MeasurementName |
|---|---|---|---|---|
| S_01 | 129C | S1 | 1 | S_01 |
| S_02 | 129N | S1 | 1 | S_02 |
| S_03 | 130C | S1 | 1 | S_03 |
| S_04 | 130N | S1 | 1 | S_04 |
| S_05 | 126 | S2 | 1 | S_05 |
| S_06 | 127C | S2 | 1 | S_06 |
| S_07 | 127N | S2 | 1 | S_07 |
| S_08 | 128C | S2 | 1 | S_08 |
| S_09 | 128N | S2 | 1 | S_09 |
| ref | 131 | S1 | 1 | NA |
Table 1.4 shows the first 10 rows of samples.
1.1.13 References
Reference can be a certain channel, average of multiple channels, or 1. The general form is an expression with ReporterAlias names as variables. It is evaluated for each PlexID/QuantBlock combination and applied to divide reporter ion intensities within corresponding PlexID/QuantBlock.
# Create references table
references <- samples %>%
# Filter to reference channel (ReporterName == "131", ReporterAlias == "ref")
filter(ReporterName == "131") %>%
# Select required columns and rename ReporterAlias to Reference
select(PlexID, Reference = ReporterAlias, QuantBlock)| PlexID | Reference | QuantBlock |
|---|---|---|
| S1 | ref | 1 |
| S2 | ref | 1 |
Table 1.5 shows the first 10 rows of references. The code to use the geometric average instead of a single channel as the reference is shown below. The geometric average is the product of the reporter ion channels to the power of (1/number of channels). For each PlexID group, collapse the vector of reporter ion names with *, surround them in parentheses, and raise to the power of (1/number of channels).
# Use geometric average as reference
references <- samples %>%
group_by(PlexID, QuantBlock) %>%
summarise(Reference = sprintf("(%s)^(1/%d)",
paste(ReporterAlias, collapse = "*"), n()))
# Do not normalize by reference channel (use 1 as the reference)
references <- samples %>%
distinct(PlexID, QuantBlock) %>%
mutate(Reference = 1)Now that we have the three study design tables, we should save them.
# Save study design tables
write.table(fractions, file = "data/fractions.txt",
sep = "\t", quote = FALSE, row.names = FALSE)
write.table(samples, file = "data/samples.txt",
sep = "\t", quote = FALSE, row.names = FALSE)
write.table(references, file = "data/references.txt",
sep = "\t", quote = FALSE, row.names = FALSE)1.1.14 Create Quantitative Cross-tab
This is the step where MS/MS IDs and reporter ions are linked together and aggregated to the peptide or accession (i.e. protein) level. To retain protein IDs while aggregating to peptide level, set aggregation_level <- c("accession","peptide"). The abundances are converted to relative abundances by dividing by the reference and then \(log_2\)-transformed.
# Set aggregation level
aggregation_level <- c("accession")
# Create cross-tab
crosstab <- create_crosstab(msnid, masic_data,
aggregation_level = aggregation_level,
fractions, samples, references)| R_01 | R_02 | R_03 | R_04 | R_05 | R_06 | R_07 | R_08 | R_09 | S_01 | S_02 | S_03 | S_04 | S_05 | S_06 | S_07 | S_08 | S_09 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP_004893.1 | 0.1419768 | 0.7628195 | 0.1653552 | 0.8662554 | 0.9453172 | -0.8794712 | -0.1912097 | 0.3964607 | -0.2440478 | -0.6460065 | -1.9294467 | -0.4321433 | -1.2831873 | -1.0271227 | -0.9390945 | 0.4883309 | -1.7148628 | -0.7029685 |
| AP_004894.1 | 0.8092676 | -0.0976095 | -0.3113350 | 0.3215692 | 0.2171255 | -1.3515366 | -0.7462995 | -0.8338103 | -0.2227493 | -0.3678781 | -0.1638689 | -0.6696829 | -1.2039041 | -0.5124954 | -0.2364175 | -0.4428327 | -1.3730408 | -0.6711809 |
| AP_004895.1 | 0.2078433 | -0.2867209 | -0.6089756 | -0.1162062 | -0.3840271 | -0.6780284 | -0.6102404 | -0.3896190 | -0.1548544 | -1.1240967 | -0.6908468 | -0.6652575 | -0.7140383 | 0.2717217 | -0.1448289 | -0.1200736 | -0.6435709 | -0.4287771 |
| AP_004896.1 | -0.1494849 | -0.3664339 | -0.7314368 | -0.1742391 | -0.5352280 | -0.6543311 | -0.6741064 | -0.3994149 | -0.0441485 | -1.2945071 | -1.0372327 | -0.7060783 | -0.8299749 | 0.1939540 | -0.2274358 | -0.1688422 | -0.5251264 | -0.4222698 |
| AP_004898.1 | 0.0362964 | 0.7497227 | 0.4252227 | 0.4913660 | 1.1580326 | -1.8439756 | -0.1774225 | -1.1083199 | -0.4175363 | 0.1211536 | -0.3640632 | -0.3019505 | -0.8291744 | -0.8407749 | -0.2796091 | -0.4130732 | -1.5747761 | -0.9449498 |
| AP_004899.1 | 0.7140968 | -0.1781542 | -0.3732752 | 0.3494902 | -0.0615626 | -1.0482424 | -0.8052899 | -0.6675429 | -0.3959923 | -2.1679002 | -0.8550940 | -0.9026145 | -1.4519278 | -0.3158081 | -0.4056811 | -0.4644758 | -0.2805080 | -0.9023044 |
Now that we have the cross-tab, we should save it.
# Save cross-tab
write.table(crosstab, file = "data/global_quant_crosstab.txt",
sep = "\t", quote = FALSE, row.names = TRUE)We will also save the proteins (row names) of this cross-tab in order to demonstrate prioritized inference in Section 1.2.
# Save global proteins
global_proteins <- rownames(crosstab)
save(global_proteins, file = "data/3442_global_proteins.RData")1.1.15 Create MSnSet Object
The final step is to create an MSnSet object, which is necessary for downstream data analysis tools such as the plot_pca_* or limma_* functions in MSnSet.utils. An MSnSet combines three tables into one object: exprs, fData, and pData. exprs is a matrix of protein abundance data with proteins as rows and samples as columns. fData is used to convert between different feature IDs such as RefSeq, UniProt accession, Entrez gene ID, gene symbol, etc. It is optional, but the rownames of fData must be the same as the row names of exprs. Lastly, pData contains the metadata with samples as rows, and the row names must be the same as the column names of exprs (same order as well). For this example, we don’t have an actual metadata table. We just know group assignment from the sample names. Samples with an “R” are part of the exeRcised group, while samples with an “S” are part of the Sedentary group. We can make a metadata table with a single column called group.
metadata <- data.frame(group = gsub("([RS]).*", "\\1", colnames(crosstab))) %>%
mutate(group = ifelse(group == "R", "exercised", "sedentary"))
rownames(metadata) <- colnames(crosstab)| group | |
|---|---|
| R_01 | exercised |
| R_02 | exercised |
| R_03 | exercised |
| R_04 | exercised |
| R_05 | exercised |
| R_06 | exercised |
| R_07 | exercised |
| R_08 | exercised |
| R_09 | exercised |
| S_01 | sedentary |
| S_02 | sedentary |
| S_03 | sedentary |
| S_04 | sedentary |
| S_05 | sedentary |
| S_06 | sedentary |
| S_07 | sedentary |
| S_08 | sedentary |
| S_09 | sedentary |
Since we used the sample data to create the metadata, everything is in the right order; however, we usually need to reorder the rows of the metadata. We can do this with
# Reorder rows of metadata to match sample order in crosstab
# Need to add drop = FALSE if the metadata is a single column
metadata <- metadata[colnames(crosstab), , drop = FALSE]We have the metadata and protein abundance data, so we can now create the MSnSet. We will call it m1 and we should save it as an .RData file.
# Create MSnSet
m1 <- MSnbase::MSnSet(exprs = as.matrix(crosstab), pData = metadata)
validObject(m1)## [1] TRUEIf we type the name of the MSnSet in the console, a summary will be displayed. This will show information about each of the tables, and the MSnSet will keep track of all processing done such as filtering at the bottom under “Processing information.”
# Display summary
m1## MSnSet (storageMode: lockedEnvironment)
## assayData: 5178 features, 18 samples
## element names: exprs
## protocolData: none
## phenoData
## sampleNames: R_01 R_02 ... S_09 (18 total)
## varLabels: group
## varMetadata: labelDescription
## featureData: none
## experimentData: use 'experimentData(object)'
## Annotation:
## - - - Processing information - - -
## MSnbase version: 2.18.0# Save unprocessed MSnSet
save(m1, file = "data/global_msnset.RData")